Overview
The Power Search is a feature that allows users to search for entities, leveraging full-text search and configurable filters. The search is performed on the indexed fields of the entity descriptor, which have been optimized for search operations. The platform team is able to configure the fields to be indexed and their relevance, to optimize the search results; they also can specify filters and configurations relative to the collators.
Power Search functionalities
The functionalities that leverage the power search are as follows:
| ID | Functionality | Description |
|---|---|---|
marketplace-projects | Marketplace Search | The search page in the marketplace, where users can search for published projects. |
provisioning-consumables | Entity Search Picker | A configurable entity picker designed to facilitate the selection of entities within the platform. |
The ID of the functionality is used to configure the search filters and indexing fields for each functionality.
How to configure the Power Search
As mentioned earlier, the platform team can customize two main areas: resource indexing and search filters.
Resource Indexing
Resource indexing is a process where specific fields are selected and indexed to make them searchable via full-text search. The platform team can choose which fields to index and for which functionality, and assign relevance levels to them. When a user enters a term in the search bar, the search engine will look for that term in the indexed fields and select results based on relevance.
Indexing configuration
The platform team has the ability to configure the fields to be indexed from the descriptor, and their relevance. For example, if the descriptors have fields like 'name', 'description', 'tags', and they believe users are more likely to search using these fields, they can configure these fields to be indexed and their relevance to be high.
The platform administrators can write the configuration in the ui.appConfig.mesh.search.functionality-id.indexFields section of the configuration file, where "functionality-id" is the ID of the functionality that will use the power search feature.
The configuration is a list of objects, each object representing a field that will be indexed. Each object will have the following fields:
- path: The path to the field in the document. For nested fields, you can use dot notation to access them (e.g.
address.city.name) and you can also navigate through arrays. - relevance: The relevance of the field in the search, represented by a letter from A to D, where A is the most relevant and D is the least relevant. You can use the same relevance level for multiple fields.
As introduced, when defining the path parameter, you can use the dot notation to access nested fields. For example, if you have a field called specific that contains a field called description, you can access it using specific.description.
This configuration can also navigate values nested inside arrays. So, for example, given a document like:
{
"tags": [
{ "name": "tag1", "description": "description1" },
{ "name": "tag2", "description": "description2" }
]
}
you could access all the tags in the descriptor using the path tags, or you could index just the tag names using the path tags.name. In the first case, documents will be returned also when searching for "tag1", "tag2", "description1" or "description2", while in the second case, the will be returned only when searching for "tag1" or "tag2".
Example configuration
This is an example configuration for the following descriptor snippet:
{
"name": "My Resource",
"specific": {
"description": "This is a description of the resource"
},
"tags": [
{
"source": "Tag",
"tagFQN": "experimental",
"labelType": "Manual"
},
{
"source": "Tag",
"tagFQN": "structured",
"labelType": "Automatic"
}
]
}
# inside your values.yaml
ui:
appConfig:
# ... other configurations ...
mesh:
search:
my-functionality-id:
indexFields:
- path: name
relevance: A
- path: specific.description
relevance: B
- path: tags.tagFQN
relevance: C
Search Filters
The search functionalities will feature a set of filters that users can use in the UI to narrow down search results. These filters are customizable by the platform administrators, who can choose which fields will be shown to the end users as filters, and how each filter will be applied when searching.
Filter structure
Each filter is represented as an object that defines a single filter condition. Each object has the following fields:
field: The field name in the document. For nested fields, you can use dot notation to access them.label: A human-readable label that will be shown in the UI.type: The type of the filter.
When defining the field parameter, you can use the _computedInfo object to access computed fields. For example, to access the domain name in the _computedInfo object, you can use _computedInfo.domain.name. Another field worth mentioning is _computedInfo.publishedAt, which can be used to filter by the publication date of the document.
In addition, the field parameter can navigate through arrays, to get all the nested values. FOr example, if your document has a structure like:
{
title: 'Example',
documentId: '1738263',
tags: [
{ id: '1', value: { name: 'pii', descriptions: [{ value: 'private' }] } },
{
id: '2',
value: {
name: 'gdpr',
descriptions: [{ value: 'sensitive' }, { value: 'personal' }],
},
},
],
}
and you want to filter based on the tag descriptions, you can use the following path: tags.value.descriptions.value.
With that configuration, the filter will search for the input string in all the descriptions of all the tags: 'private', 'sensitive', and 'personal'.
Filter types
Filters can be of the following types:
text: a free-form text field. Just input the text and the search engine will look for it in the filter field.choice: a multiple-choice box with pre-defined values.domain: a multiple-choice box where the values are witboost's domains displayed in a tree structure that resembles their parent-child relationshipstype: a multiple-choice box where the values are witboost's types of systems and componentsboolean: a simple toggle. You can use this filter only on boolean values.consumable: a simple toggle like boolean, but specifically matches if the value in the specified field is considered Consumablefavorites: a simple toggle like boolean for entities starred by the userdate: a date picker. You can use this filter only on date fields. The field should be in the Date Time String Format, and you can omit fields after the day, or use the Unix Epoch.
The text filter admits an additional configuration field called match. This field tells Witboost how the input string should be matched with the existing values, and can have the following values:
exact: The input string must match the existing values exactly.begins: The input string must be a prefix of the existing values. This is the default value.ends: The input string must be a suffix of the existing values.contains: The input string must be contained in one of the existing values.
Since the ends and contains options are more computationally expensive, it is recommended to use them only when necessary. The comparison is case-insensitive.
Filter configuration
Marketplace products
For marketplace products, the platform team can configure and modify filters directly from the user interface in the Administration > Configuration > Search Filters section.
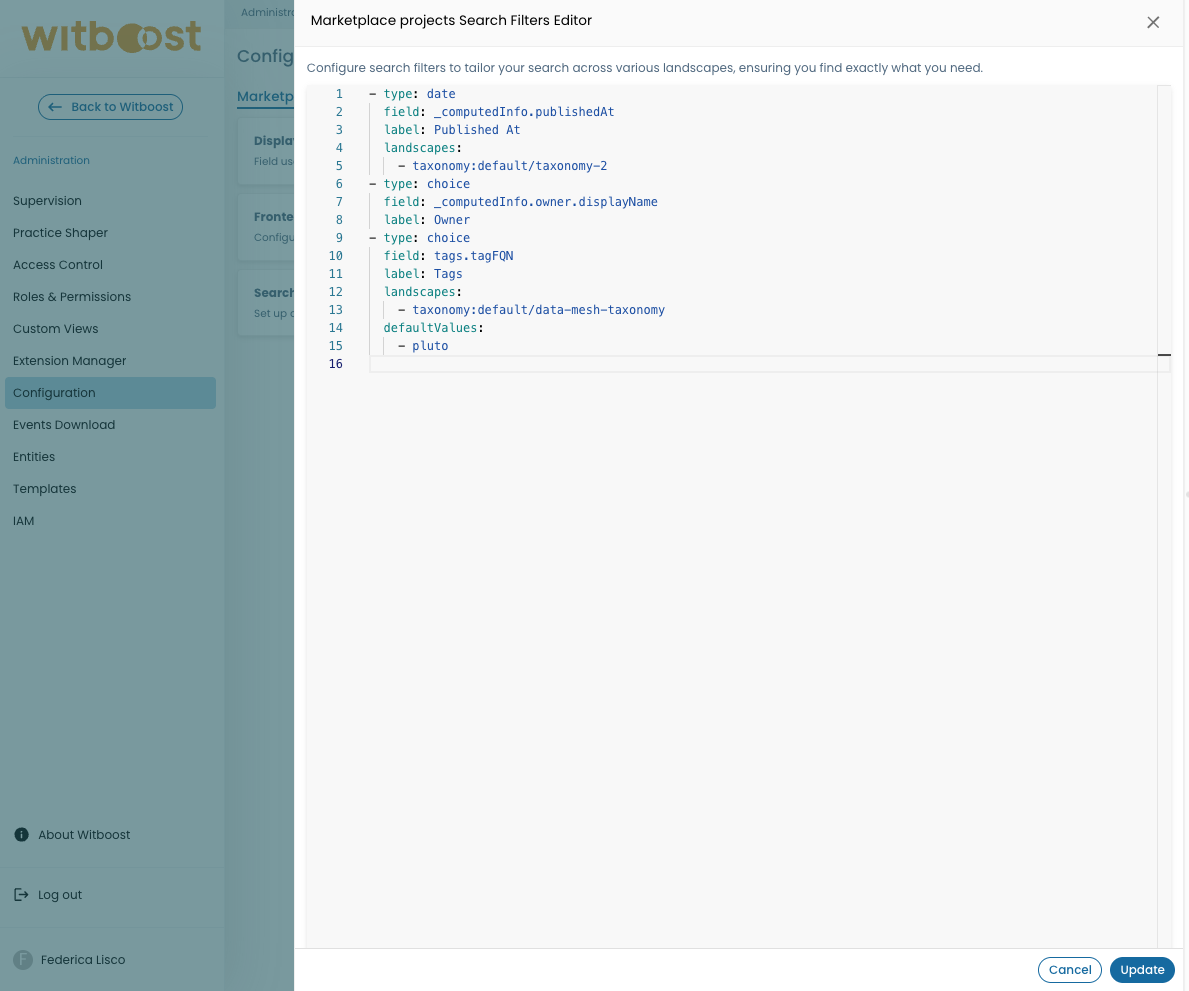
Each functionality that utilizes the power search feature will use this set of filters. Remember that the filter path and label must be unique within the same functionality.
Example configuration
Given the following descriptor snippet:
{
"domain": "finance",
"tags": [
{
"source": "Tag",
"tagFQN": "experimental",
"labelType": "Manual"
},
{
"source": "Tag",
"tagFQN": "structured",
"labelType": "Automatic"
}
],
"deploymentInfo": {
"status": "COMPLETED",
"deploymentDate": "2021-09-01T00:00:00Z",
"deploymentId": "123456",
"deploymentType": "MANUAL"
},
"consumable": true
}
an example configuration in the Marketplace Search functionality could be:
marketplace-projects:
filters:
- field: domain
label: Domain
type: choice
- field: tags.tagFQN
label: Tags
type: text
- field: deploymentInfo.deploymentDate
label: Deployment Date
type: date
- field: consumable
label: Consumable
type: boolean
Default filters
There are some filters included by default in some of the collators, which are included. These filters are:
marketplace-projects:
filters:
- field: '_computedInfo.environment'
label: 'Environment'
type: 'choice'
- field: '_computedInfo.taxonomy.external_id'
label: 'Data Landscape'
type: 'choice'
- field: 'kind',
label: 'Type',
type: 'type'
- field: '_computedInfo.consumable'
label: 'Consumable'
type: 'consumable'
- field: '_computedInfo.domain.external_id'
label: 'Domain'
type: 'domain'
- field: 'id'
label: 'Favorites'
type: 'favorites'
Default values and additional options
Filters support additional configuration options:
defaultValues: An optional array of strings representing pre-selected values that are automatically applied when users first access the search interface.landscapes: An optional array of landscape identifiers (e.g.taxonomy:default/data-mesh-taxonomy). When specified, the filter will only be shown in the filter list when one of the specified landscapes is currently selected.
Example
- field: _computedInfo.owner.displayName
label: Owner
type: choice
landscapes:
- taxonomy:default/data-mesh-taxonomy
- field: tags
label: Tags
type: choice
- field: kind
# Optional default values for a pre defined filter
defaultValues:
- 'dataproduct'
- field: _computedInfo.domain.external_id
label: Domain
type: domain
defaultValues:
- 'urn:dmb:dmn:finance'
- 'urn:dmb:dmn:marketing'
This configuration creates four filters in the marketplace search interface:
- Owner Filter: This filter will only be available/visible when the 'data-mesh-taxonomy' landscape is selected.
- Tags Filter: Always visible but has no default values, allowing users to filter by tags as needed.
- Kind Filter: Pre-selects only data products (excluding other system types).
- Domain Filter: Automatically filters results to show only data products from Finance and Marketing domains.
When users access the marketplace search for the first time, these filters will already be applied, showing relevant data products. Users can then modify or remove these filters as needed.
For the pre-defined filters fields (i.e. type, domain from the above section), you can only define the key defaultValues. All the others will be ignored.
If no default values are provided, no filters will be pre-set in the UI.
Provisioning consumables default filters
There are some filters included by default in the provisioning consumables collator, which are not configurable by the platform team. These filters are:
provisioning-consumables:
filters:
- field: 'domain'
label: 'Domain'
type: 'choice'
- field: 'deploymentUnitId'
label: 'Parent'
type: 'choice'
- field: 'environment'
label: 'Environment'
type: 'choice'
- field: 'kind'
label: 'Kind'
type: 'choice'
Collator scheduling configuration
Configuration
The platform team can configure the collators using the following configuration:
# inside your values.yaml
ui:
appConfig:
# ... other configurations ...
mesh:
search:
marketplace-projects:
schedule:
frequency:
minutes: 10
timeout:
minutes: 15
initialDelay:
seconds: 3
collatorOptions:
batchSize: 100
provisioning-consumables:
schedule:
frequency:
minutes: 10
timeout:
minutes: 15
initialDelay:
seconds: 3
collatorOptions:
batchSize: 100
Configuration Parameters:
- Frequency: The interval at which the collator ingests all documents again, specified in minutes.
- Timeout: The maximum time allowed for the collator to ingest all documents, specified in minutes.
- InitialDelay: The time the collator waits before starting the ingestion, specified in seconds.
- BatchSize: The number of documents to be ingested in each batch.
Note that if you set schedule, you will have to set all its subfields frequency, timeout, and initialDelay.
Custom views
The Search Results page supports custom views that can be configured by the platform team.
These views allow the platform team to define how the search results are displayed to the end users.
There two types of custom views: marketplace_search_system and marketplace_search_component, and they can be
downloaded from the menu next to the page title "Search". For more information on how to configure custom views, refer to the Custom Views documentation.